Applying Structured Output to RAG applications¶
What is RAG?
Retrieval Augmented Generation (RAG) models are the bridge between large language models and external knowledge databases. They fetch the relevant data for a given query. For example, if you have some documents and want to ask questions related to the content of those documents, RAG models help by retrieving data from those documents and passing it to the LLM in queries.
How do RAG models work?
The typical RAG process involves embedding a user query and searching a vector database to find the most relevant information to supplement the generated response. This approach is particularly effective when the database contains information closely matching the query but not more than that.

Why is there a need for them?
Pre-trained large language models do not learn over time. If you ask them a question they have not been trained on, they will often hallucinate. Therefore, we need to embed our own data to achieve a better output.
Simple RAG¶
What is it?
The simplest implementation of RAG embeds a user query and do a single embedding search in a vector database, like a vector store of Wikipedia articles. However, this approach often falls short when dealing with complex queries and diverse data sources.
- Query-Document Mismatch: It assumes that the query and document embeddings will align in the vector space, which is often not the case.
- Text Search Limitations: The model is restricted to simple text queries without the nuances of advanced search features.
- Limited Planning Ability: It fails to consider additional contextual information that could refine the search results.
Improving the RAG model¶
What's the solution?
Enhancing RAG requires a more sophisticated approach known as query understanding.
This process involves analyzing the user's query and transforming it to better match the backend's search capabilities.
By doing so, we can significantly improve both the precision and recall of the search results, providing more accurate and relevant responses.
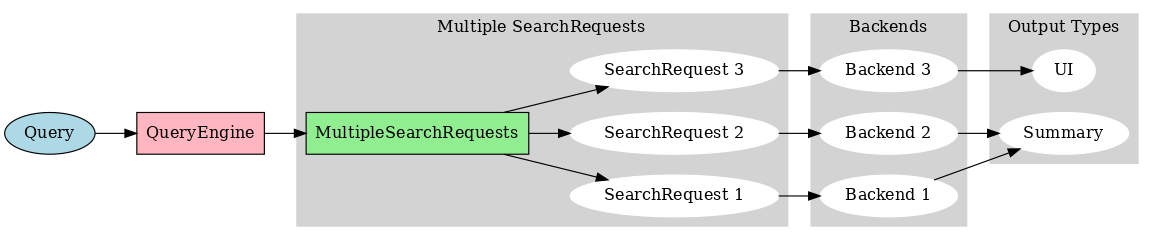
Practical Examples¶
In the examples below, we're going to use the instructor library to simplify the interaction between the programmer and language models via the function-calling API.
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
client = instructor.patch(OpenAI())
Example 1) Improving Extractions¶
One of the big limitations is that often times the query we embed and the text we are searching for may not have a direct match, leading to suboptimal results. A common method of using structured output is to extract information from a document and use it to answer a question. Directly, we can be creative in how we extract, summarize and generate potential questions in order for our embeddings to do better.
For example, instead of using just a text chunk we could try to:
- extract key words and themes
- extract hypothetical questions
- generate a summary of the text
In the example below, we use the instructor library to extract the key words and themes from a text chunk and use them to answer a question.
class Extraction(BaseModel):
topic: str
summary: str
hypothetical_questions: list[str] = Field(
default_factory=list,
description="Hypothetical questions that this document could answer",
)
keywords: list[str] = Field(
default_factory=list, description="Keywords that this document is about"
)
from pprint import pprint
from collections.abc import Iterable
text_chunk = """
## Simple RAG
**What is it?**
The simplest implementation of RAG embeds a user query and do a single embedding search in a vector database, like a vector store of Wikipedia articles. However, this approach often falls short when dealing with complex queries and diverse data sources.
**What are the limitations?**
- **Query-Document Mismatch:** It assumes that the query and document embeddings will align in the vector space, which is often not the case.
- Query: "Tell me about climate change effects on marine life."
- Issue: The model might retrieve documents related to general climate change or marine life, missing the specific intersection of both topics.
- **Monolithic Search Backend:** It relies on a single search method and backend, reducing flexibility and the ability to handle multiple data sources.
- Query: "Latest research in quantum computing."
- Issue: The model might only search in a general science database, missing out on specialized quantum computing resources.
- **Text Search Limitations:** The model is restricted to simple text queries without the nuances of advanced search features.
- Query: "what problems did we fix last week"
- Issue: cannot be answered by a simple text search since documents that contain problem, last week are going to be present at every week.
- **Limited Planning Ability:** It fails to consider additional contextual information that could refine the search results.
- Query: "Tips for first-time Europe travelers."
- Issue: The model might provide general travel advice, ignoring the specific context of first-time travelers or European destinations.
"""
extractions = client.chat.completions.create(
model="gpt-4-1106-preview",
stream=True,
response_model=Iterable[Extraction],
messages=[
{
"role": "system",
"content": "Your role is to extract chunks from the following and create a set of topics.",
},
{"role": "user", "content": text_chunk},
],
)
for extraction in extractions:
pprint(extraction.model_dump())
{'hypothetical_questions': ['What is the basic concept behind simple RAG?',
'How does simple RAG work for information '
'retrieval?'],
'keywords': ['Simple RAG',
'Retrieval-Augmented Generation',
'user query',
'embedding search',
'vector database',
'Wikipedia articles',
'information retrieval'],
'summary': 'The simplest implementation of Retrieval-Augmented Generation '
'(RAG) involves embedding a user query and conducting a single '
'embedding search in a vector database, like a vector store of '
'Wikipedia articles, to retrieve relevant information. This method '
'may not be ideal for complex queries or varied data sources.',
'topic': 'Simple RAG'}
{'hypothetical_questions': ['What are the drawbacks of using simple RAG '
'systems?',
'How does query-document mismatch affect the '
'performance of RAG?',
'Why is a monolithic search backend a limitation '
'for RAG?'],
'keywords': ['limitations',
'query-document mismatch',
'simple RAG',
'monolithic search backend',
'text search',
'planning ability',
'contextual information'],
'summary': 'Key limitations of the simple RAG include query-document '
'mismatch, reliance on a single search backend, constraints of '
'text search capabilities, and limited planning ability to '
'leverage contextual information. These issues can result in '
'suboptimal search outcomes and retrieval of irrelevant or broad '
'information.',
'topic': 'Limitations of Simple RAG'}
Now you can imagine if you were to embed the summaries, hypothetical questions, and keywords in a vector database (i.e. in the metadata fields of a vector database), you can then use a vector search to find the best matching document for a given query. What you'll find is that the results are much better than if you were to just embed the text chunk!
Example 2) Understanding 'recent queries' to add temporal context¶
One common application of using structured outputs for query understanding is to identify the intent of a user's query. In this example we're going to use a simple schema to seperately process the query to add additional temporal context.
from datetime import date
class DateRange(BaseModel):
start: date
end: date
class Query(BaseModel):
rewritten_query: str
published_daterange: DateRange
In this example, DateRange and Query are Pydantic models that structure the user's query with a date range and a list of domains to search within.
These models restructure the user's query by including a rewritten query, a range of published dates, and a list of domains to search in.
Using the new restructured query, we can apply this pattern to our function calls to obtain results that are optimized for our backend.
def expand_query(q) -> Query:
return client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=Query,
messages=[
{
"role": "system",
"content": f"You're a query understanding system for the Metafor Systems search engine. Today is {date.today()}. Here are some tips: ...",
},
{"role": "user", "content": f"query: {q}"},
],
)
query = expand_query("What are some recent developments in AI?")
query
Query(rewritten_query='Recent developments in artificial intelligence', published_daterange=DateRange(start=datetime.date(2024, 1, 1), end=datetime.date(2024, 3, 31)))
This isn't just about adding some date ranges. We can even use some chain of thought prompting to generate tailored searches that are deeply integrated with our backend.
class DateRange(BaseModel):
chain_of_thought: str = Field(
description="Think step by step to plan what is the best time range to search in"
)
start: date
end: date
class Query(BaseModel):
rewritten_query: str = Field(
description="Rewrite the query to make it more specific"
)
published_daterange: DateRange = Field(
description="Effective date range to search in"
)
def expand_query(q) -> Query:
return client.chat.completions.create(
model="gpt-4-1106-preview",
response_model=Query,
messages=[
{
"role": "system",
"content": f"You're a query understanding system for the Metafor Systems search engine. Today is {date.today()}. Here are some tips: ...",
},
{"role": "user", "content": f"query: {q}"},
],
)
expand_query("What are some recent developments in AI?")
Query(rewritten_query='latest advancements in artificial intelligence', published_daterange=DateRange(chain_of_thought='Since the user is asking for recent developments, it would be relevant to look for articles and papers published within the last year. Therefore, setting the start date to a year before today and the end date to today will cover the most recent advancements.', start=datetime.date(2023, 3, 31), end=datetime.date(2024, 3, 31)))
Using Weights and Biases to track experiments¶
While running a function like this production is quite simple, a lot of time will be spend on iterating and improving the model. To do this, we can use Weights and Biases to track our experiments.
In order to do so we wand manage a few things
- Save input and output pairs for later
- Save the JSON schema for the response_model
- Having snapshots of the model and data allow us to compare results over time, and as we make changes to the model we can see how the results change.
This is particularly useful when we might want to blend a mix of synthetic and real data to evaluate our model. We can use the wandb library to track our experiments and save the results to a dashboard.
import json
import instructor
from openai import AsyncOpenAI
from datetime import date
from pydantic import BaseModel, Field
class DateRange(BaseModel):
chain_of_thought: str = Field(
description="Think step by step to plan what is the best time range to search in"
)
start: date
end: date
class Query(BaseModel):
rewritten_query: str = Field(
description="Rewrite the query to make it more specific"
)
published_daterange: DateRange = Field(
description="Effective date range to search in"
)
def report(self):
dct = self.model_dump()
dct["usage"] = self._raw_response.usage.model_dump()
return dct
# We'll use a different client for async calls
# To highlight the difference and how we can use both
aclient = instructor.patch(AsyncOpenAI())
async def expand_query(
q, *, model: str = "gpt-4-1106-preview", temp: float = 0
) -> Query:
return await aclient.chat.completions.create(
model=model,
temperature=temp,
response_model=Query,
messages=[
{
"role": "system",
"content": f"You're a query understanding system for the Metafor Systems search engine. Today is {date.today()}. Here are some tips: ...",
},
{"role": "user", "content": f"query: {q}"},
],
)
# % pip install pandas wandb
import pandas as pd
from typing import Any
def flatten_dict(d: dict[str, Any], parent_key: str = "", sep: str = "_") -> dict[str, Any]:
"""
Flatten a nested dictionary.
:param d: The nested dictionary to flatten.
:param parent_key: The base key to use for the flattened keys.
:param sep: Separator to use between keys.
:return: A flattened dictionary.
"""
items = []
for k, v in d.items():
new_key = f"{parent_key}{sep}{k}" if parent_key else k
if isinstance(v, dict):
items.extend(flatten_dict(v, new_key, sep=sep).items())
else:
items.append((new_key, v))
return dict(items)
def dicts_to_df(list_of_dicts: list[dict[str, Any]]) -> pd.DataFrame:
"""
Convert a list of dictionaries to a pandas DataFrame.
:param list_of_dicts: List of dictionaries, potentially nested.
:return: A pandas DataFrame representing the flattened data.
"""
# Flatten each dictionary and create a DataFrame
flattened_data = [flatten_dict(d) for d in list_of_dicts]
return pd.DataFrame(flattened_data)
import asyncio
import time
import pandas as pd
import wandb
model = "gpt-4-1106-preview"
temp = 0
run = wandb.init(
project="query",
config={"model": model, "temp": temp},
)
test_queries = [
"latest developments in artificial intelligence last 3 weeks",
"renewable energy trends past month",
"quantum computing advancements last 2 months",
"biotechnology updates last 10 days",
]
start = time.perf_counter()
queries = await asyncio.gather(
*[expand_query(q, model=model, temp=temp) for q in test_queries]
)
duration = time.perf_counter() - start
with open("schema.json", "w+") as f:
schema = Query.model_json_schema()
json.dump(schema, f, indent=2)
with open("results.jsonlines", "w+") as f:
for query in queries:
f.write(query.model_dump_json() + "\n")
df = dicts_to_df([q.report() for q in queries])
df["input"] = test_queries
df.to_csv("results.csv")
run.log({"schema": wandb.Table(dataframe=pd.DataFrame([{"schema": schema}]))})
run.log(
{
"usage_total_tokens": df["usage_total_tokens"].sum(),
"usage_completion_tokens": df["usage_completion_tokens"].sum(),
"usage_prompt_tokens": df["usage_prompt_tokens"].sum(),
"duration (s)": duration,
"average duration (s)": duration / len(queries),
"n_queries": len(queries),
}
)
run.log(
{
"results": wandb.Table(dataframe=df),
}
)
files = wandb.Artifact("data", type="dataset")
files.add_file("schema.json")
files.add_file("results.jsonlines")
files.add_file("results.csv")
run.log_artifact(files)
run.finish()
The output of Weights and Biases would return something like the below table.
| Metric | Value |
|---|---|
| average duration (s) | 1.5945 |
| duration (s) | 6.37799 |
| n_queries | 4 |
| usage_completion_tokens | 376 |
| usage_prompt_tokens | 780 |
| usage_total_tokens | 1156 |
Example 3) Personal Assistants, parallel processing¶
A personal assistant application needs to interpret vague queries and fetch information from multiple backends, such as emails and calendars. By modeling the assistant's capabilities using Pydantic, we can dispatch the query to the correct backend and retrieve a unified response.
For instance, when you ask, "What's on my schedule today?", the application needs to fetch data from various sources like events, emails, and reminders. This data is stored across different backends, but the goal is to provide a consolidated summary of results.
It's important to note that the data from these sources may not be embedded in a search backend. Instead, they could be accessed through different clients like a calendar or email, spanning both personal and professional accounts.
from typing import Literal
class SearchClient(BaseModel):
query: str = Field(description="The search query that will go into the search bar")
keywords: list[str]
email: str
source: Literal["gmail", "calendar"]
date_range: DateRange
class Retrieval(BaseModel):
queries: list[SearchClient]
Now, we can utilize this with a straightforward query such as "What do I have today?".
The system will attempt to asynchronously dispatch the query to the appropriate backend.
However, it's still crucial to remember that effectively prompting the language model is still a key aspect.
retrieval = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=Retrieval,
messages=[
{
"role": "system",
"content": f"""You are Jason's personal assistant.
He has two emails [email protected] [email protected]
Today is {date.today()}""",
},
{"role": "user", "content": "What do I have today for work? any new emails?"},
],
)
print(retrieval.model_dump_json(indent=4))
{
"queries": [
{
"query": "work",
"keywords": [
"work",
"today"
],
"email": "[email protected]",
"source": "gmail",
"date_range": {
"chain_of_thought": "Check today's work schedule",
"start": "2024-03-31",
"end": "2024-03-31"
}
},
{
"query": "new emails",
"keywords": [
"email",
"new"
],
"email": "[email protected]",
"source": "gmail",
"date_range": {
"chain_of_thought": "Check for new emails today",
"start": "2024-03-31",
"end": "2024-03-31"
}
}
]
}
To make it more challenging, we will assign it multiple tasks, followed by a list of queries that are routed to various search backends, such as email and calendar. Not only do we dispatch to different backends, over which we have no control, but we are also likely to render them to the user in different ways.
retrieval = client.chat.completions.create(
model="gpt-4-1106-preview",
response_model=Retrieval,
messages=[
{
"role": "system",
"content": f"""You are Jason's personal assistant.
He has two emails [email protected] [email protected]
Today is {date.today()}""",
},
{
"role": "user",
"content": "What meetings do I have today and are there any important emails I should be aware of",
},
],
)
print(retrieval.model_dump_json(indent=4))
{
"queries": [
{
"query": "Jason's meetings",
"keywords": [
"meeting",
"appointment",
"schedule",
"calendar"
],
"email": "[email protected]",
"source": "calendar",
"date_range": {
"chain_of_thought": "Since today's date is 2024-03-31, we should look for meetings scheduled for this exact date.",
"start": "2024-03-31",
"end": "2024-03-31"
}
}
]
}
Example 4) Decomposing questions¶
Lastly, a lightly more complex example of a problem that can be solved with structured output is decomposing questions. Where you ultimately want to decompose a question into a series of sub-questions that can be answered by a search backend. For example
"Whats the difference in populations of jason's home country and canada?"
You'd ultimately need to know a few things
- Jason's home country
- The population of Jason's home country
- The population of Canada
- The difference between the two
This would not be done correctly as a single query, nor would it be done in parallel, however there are some opportunities try to be parallel since not all of the sub-questions are dependent on each other.
class Question(BaseModel):
id: int = Field(..., description="A unique identifier for the question")
query: str = Field(..., description="The question decomposited as much as possible")
subquestions: list[int] = Field(
default_factory=list,
description="The subquestions that this question is composed of",
)
class QueryPlan(BaseModel):
root_question: str = Field(..., description="The root question that the user asked")
plan: list[Question] = Field(
..., description="The plan to answer the root question and its subquestions"
)
retrieval = client.chat.completions.create(
model="gpt-4-1106-preview",
response_model=QueryPlan,
messages=[
{
"role": "system",
"content": "You are a query understanding system capable of decomposing a question into subquestions.",
},
{
"role": "user",
"content": "What is the difference between the population of jason's home country and canada?",
},
],
)
print(retrieval.model_dump_json(indent=4))
{
"root_question": "What is the difference between the population of Jason's home country and Canada?",
"plan": [
{
"id": 1,
"query": "What is the population of Jason's home country?",
"subquestions": []
},
{
"id": 2,
"query": "What is the population of Canada?",
"subquestions": []
},
{
"id": 3,
"query": "What is the difference between two population numbers?",
"subquestions": [
1,
2
]
}
]
}
I hope in this section I've exposed you to some ways we can be creative in modeling structured outputs to leverage LLMS in building some lightweight components for our systems.