Generating YouTube Clips from Transcripts¶
This guide demonstrates how to generate concise, informative clips from YouTube video transcripts using the instructor library. By leveraging the power of OpenAI's models, we can extract meaningful segments from a video's transcript, which can then be recut into smaller, standalone videos. This process involves identifying key moments within a transcript and summarizing them into clips with specific titles and descriptions.
First, install the necessary packages:
from youtube_transcript_api import YouTubeTranscriptApi
from pydantic import BaseModel, Field
from typing import List, Generator, Iterable
import instructor
import instructor
client = instructor.from_provider("openai/gpt-5-nano")
def extract_video_id(url: str) -> str | None:
import re
match = re.search(r"v=([a-zA-Z0-9_-]+)", url)
if match:
return match.group(1)
class TranscriptSegment(BaseModel):
source_id: int
start: float
text: str
def get_transcript_with_timing(
video_id: str,
) -> Generator[TranscriptSegment, None, None]:
"""
Fetches the transcript of a YouTube video along with the start and end times
for each text segment, and returns them as a list of Pydantic models.
"""
transcript = YouTubeTranscriptApi.get_transcript(video_id)
for ii, segment in enumerate(transcript):
yield TranscriptSegment(
source_id=ii, start=segment["start"], text=segment["text"]
)
class YoutubeClip(BaseModel):
title: str = Field(description="Specific and informative title for the clip.")
description: str = Field(
description="A detailed description of the clip, including notable quotes or phrases."
)
start: float
end: float
class YoutubeClips(BaseModel):
clips: List[YoutubeClip]
def yield_clips(segments: Iterable[TranscriptSegment]) -> Iterable[YoutubeClips]:
return client.create(
model="gpt-4-turbo-preview",
stream=True,
messages=[
{
"role": "system",
"content": """You are given a sequence of YouTube transcripts and your job
is to return notable clips that can be recut as smaller videos. Give very
specific titles and descriptions. Make sure the length of clips is proportional
to the length of the video. Note that this is a transcript and so there might
be spelling errors. Note that and correct any spellings. Use the context to
make sure you're spelling things correctly.""",
},
{
"role": "user",
"content": f"Let's use the following transcript segments.\n{segments}",
},
],
response_model=instructor.Partial[YoutubeClips],
context={"segments": segments},
) # type: ignore
# Example usage
if __name__ == "__main__":
from rich.table import Table
from rich.console import Console
from rich.prompt import Prompt
console = Console()
url = Prompt.ask("Enter a YouTube URL")
with console.status("[bold green]Processing YouTube URL...") as status:
video_id = extract_video_id(url)
if video_id is None:
raise ValueError("Invalid YouTube video URL")
transcript = list(get_transcript_with_timing(video_id))
status.update("[bold green]Generating clips...")
for clip in yield_clips(transcript):
console.clear()
table = Table(title="Extracted YouTube Clips", padding=(0, 1))
table.add_column("Title", style="cyan")
table.add_column("Description", style="magenta")
table.add_column("Start", justify="right", style="green")
table.add_column("End", justify="right", style="green")
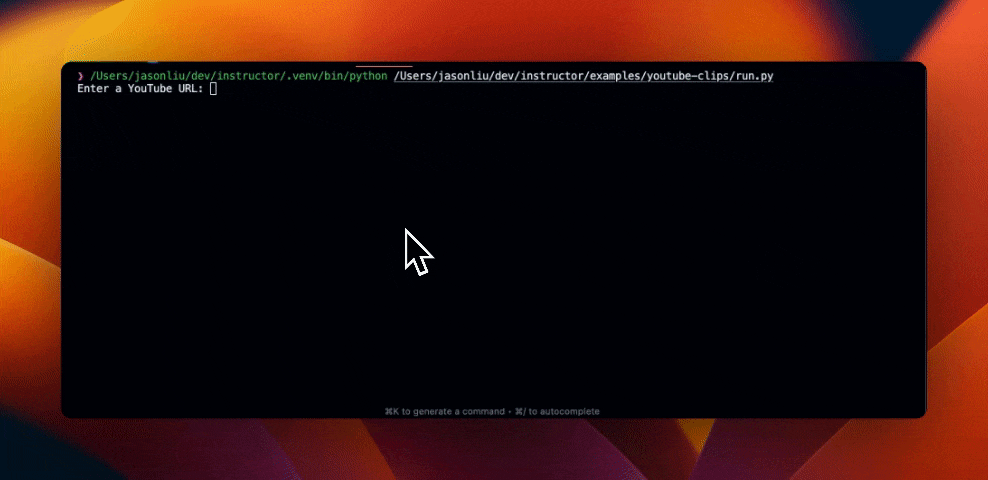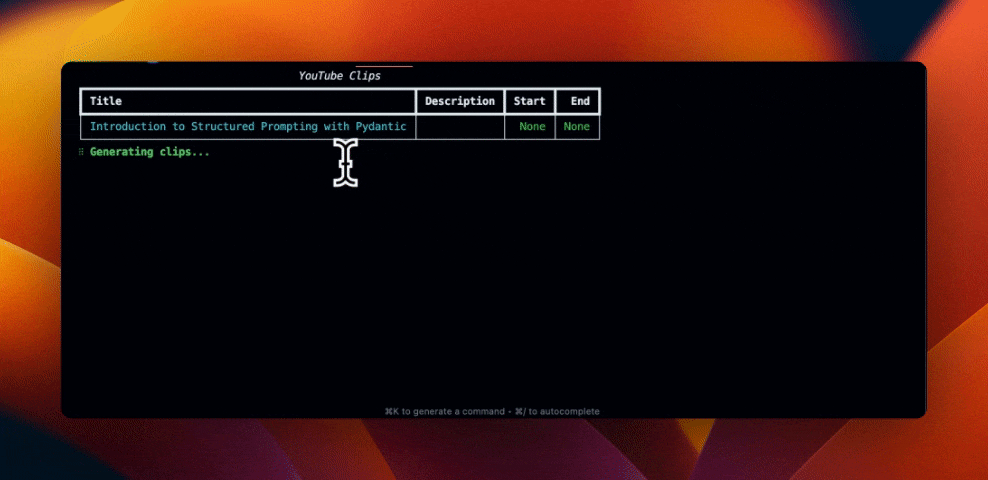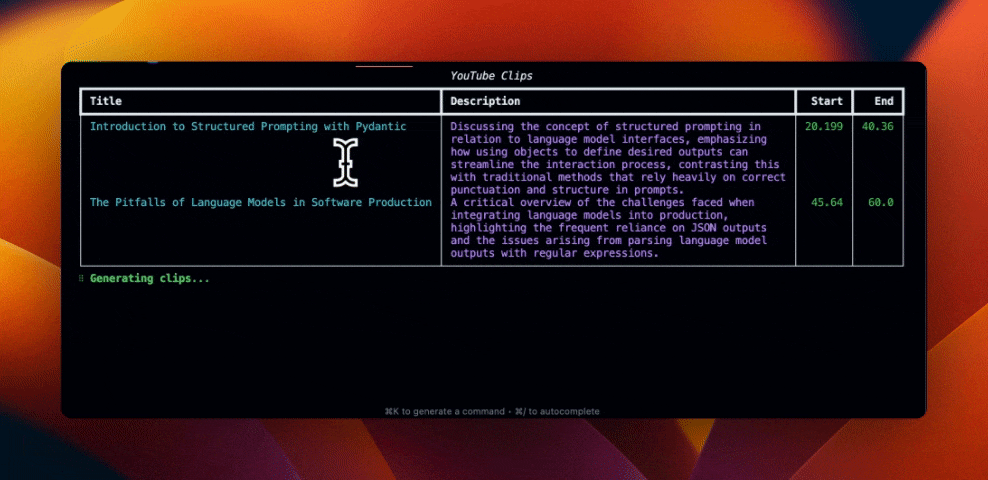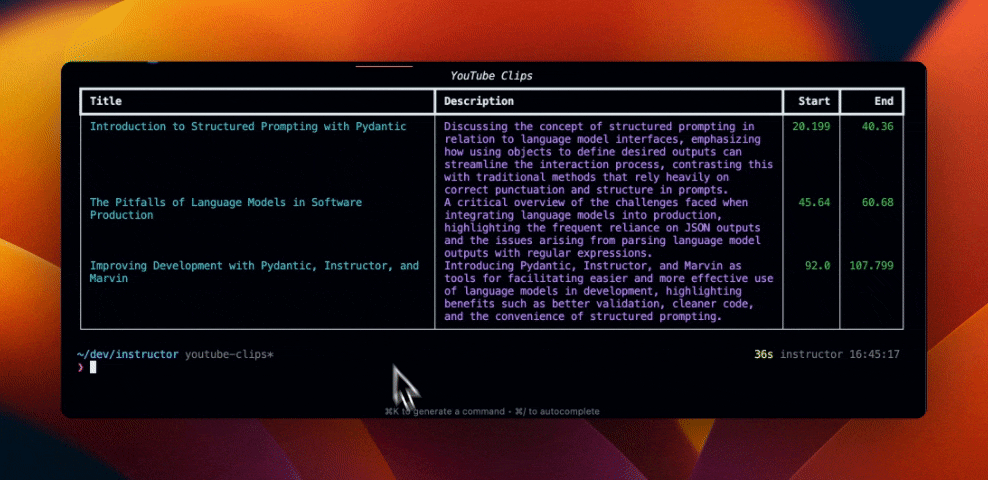
for youtube_clip in clip.clips or []:
table.add_row(
youtube_clip.title,
youtube_clip.description,
str(youtube_clip.start),
str(youtube_clip.end),
)
console.print(table)