Analyzing Youtube Transcripts with Instructor¶
Extracting Chapter Information¶
Code Snippets
As always, the code is readily available in our examples/youtube folder in our repo for your reference in the run.py file.
In this post, we'll show you how to summarise Youtube video transcripts into distinct chapters using instructor before exploring some ways you can adapt the code to different applications.
By the end of this article, you'll be able to build an application as per the video below.
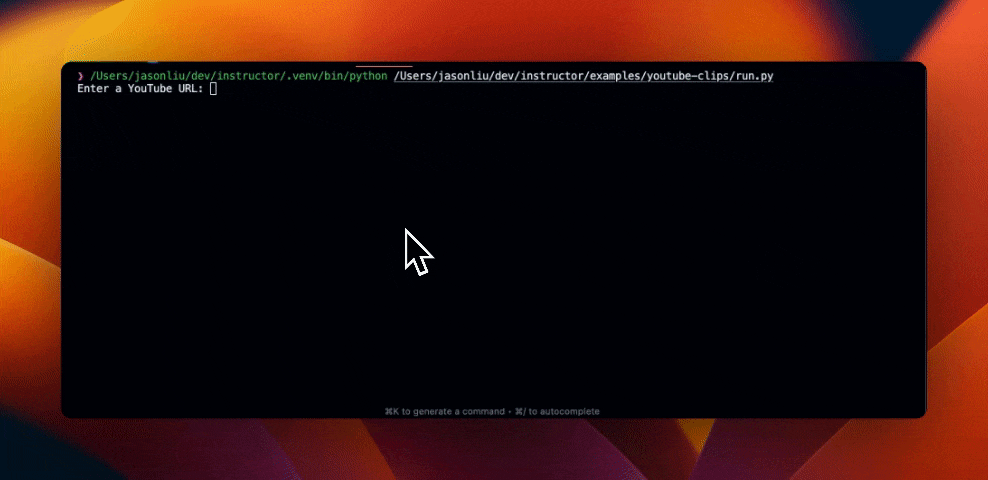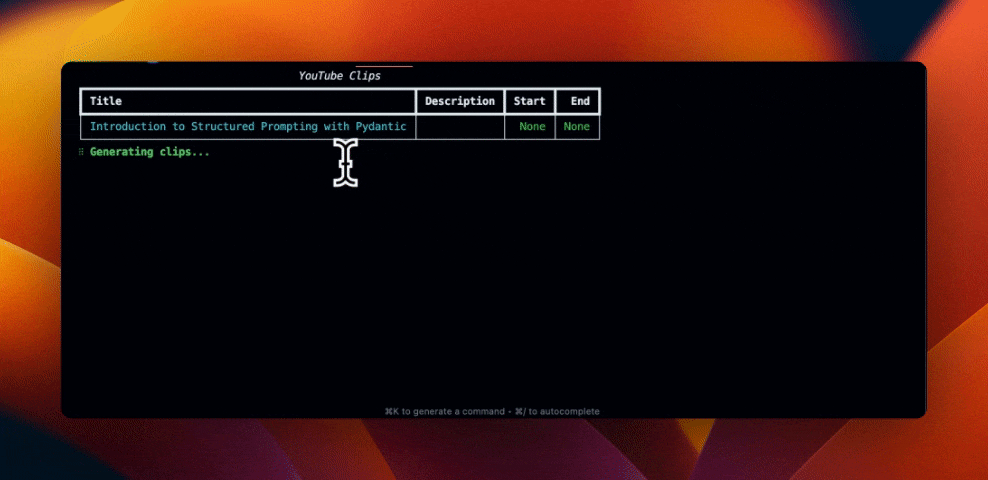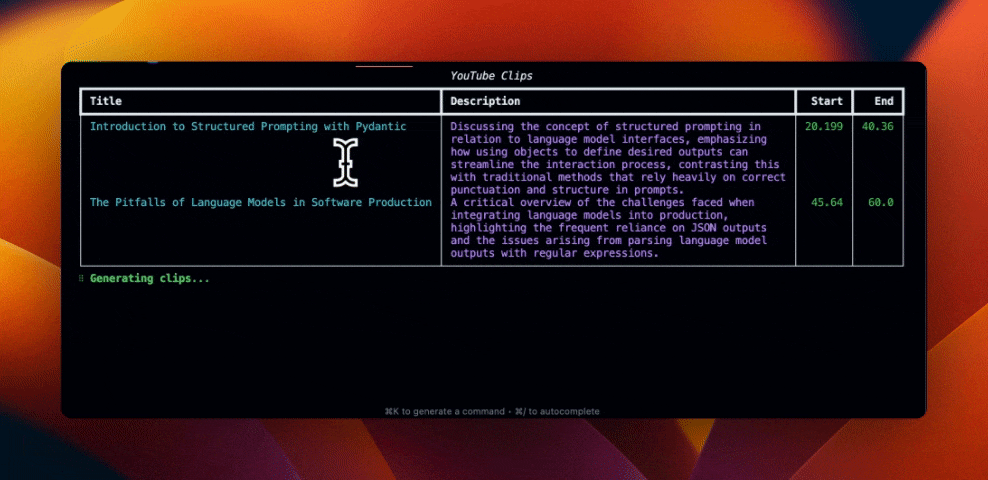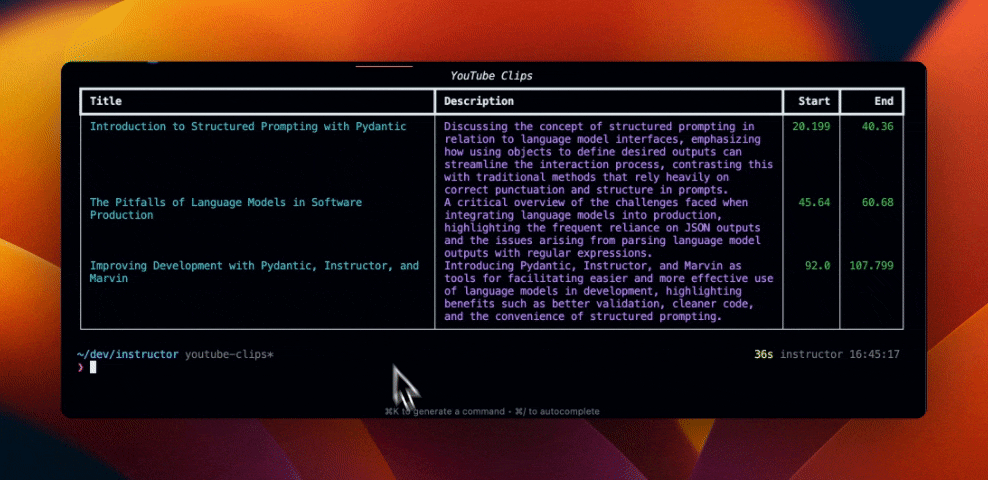
Let's first install the required packages.
Quick Note
The video that we'll be using in this tutorial is A Hacker's Guide To Language Models by Jeremy Howard. It has the video id of jkrNMKz9pWU.
Next, let's start by defining a Pydantic Model for the structured chapter information that we want.
from pydantic import BaseModel, Field
class Chapter(BaseModel):
start_ts: float = Field(
...,
description="Starting timestamp for a chapter.",
)
end_ts: float = Field(
...,
description="Ending timestamp for a chapter",
)
title: str = Field(
..., description="A concise and descriptive title for the chapter."
)
summary: str = Field(
...,
description="A brief summary of the chapter's content, don't use words like 'the speaker'",
)
We can take advantage of youtube-transcript-api to extract out the transcript of a video using the following function
from youtube_transcript_api import YouTubeTranscriptApi
def get_youtube_transcript(video_id: str) -> str:
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return " ".join(
[f"ts={entry['start']} - {entry['text']}" for entry in transcript]
)
except Exception as e:
print(f"Error fetching transcript: {e}")
return ""
Once we've done so, we can then put it all together into the following functions.
import instructor
from pydantic import BaseModel, Field
from youtube_transcript_api import YouTubeTranscriptApi
# Set up OpenAI client
client = instructor.from_provider("openai/gpt-5-nano")
class Chapter(BaseModel):
start_ts: float = Field(
...,
description="The start timestamp indicating when the chapter starts in the video.",
)
end_ts: float = Field(
...,
description="The end timestamp indicating when the chapter ends in the video.",
)
title: str = Field(
..., description="A concise and descriptive title for the chapter."
)
summary: str = Field(
...,
description="A brief summary of the chapter's content, don't use words like 'the speaker'",
)
def get_youtube_transcript(video_id: str) -> str:
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return [f"ts={entry['start']} - {entry['text']}" for entry in transcript]
except Exception as e:
print(f"Error fetching transcript: {e}")
"""
Error fetching transcript: type object 'YouTubeTranscriptApi' has no attribute 'get_transcript'
"""
return ""
def extract_chapters(transcript: str):
return client.create_iterable(
model="gpt-4o", # You can experiment with different models
response_model=Chapter,
messages=[
{
"role": "system",
"content": "Analyze the given YouTube transcript and extract chapters. For each chapter, provide a start timestamp, end timestamp, title, and summary.",
},
{"role": "user", "content": transcript},
],
)
if __name__ == "__main__":
transcripts = get_youtube_transcript("jkrNMKz9pWU")
for transcript in transcripts[:2]:
print(transcript)
#> ts=0.539 - hi I am Jeremy Howard from fast.ai and
#> ts=4.62 - this is a hacker's guide to language
formatted_transcripts = ''.join(transcripts)
chapters = extract_chapters(formatted_transcripts)
for chapter in chapters:
print(chapter.model_dump_json(indent=2))
"""
{
"start_ts": 0.0,
"end_ts": 30.0,
"title": "Introduction and Topic Overview",
"summary": "Introduction to the video, outlining the main topic of discussion."
}
"""
"""
{
"start_ts": 31.0,
"end_ts": 60.0,
"title": "Background Information",
"summary": "Background information relevant to the topic."
}
"""
"""
{
"start_ts": 61.0,
"end_ts": 120.0,
"title": "Key Concept Explanation",
"summary": "Detailed explanation of the key concepts."
}
"""
"""
{
"start_ts": 121.0,
"end_ts": 165.0,
"title": "Critical Analysis",
"summary": "Analysis and discussion of the critical aspects of the topic."
}
"""
"""
{
"start_ts": 166.0,
"end_ts": 210.0,
"title": "Examples and Case Studies",
"summary": "Presentation of examples and case studies related to the topic."
}
"""
"""
{
"start_ts": 211.0,
"end_ts": 240.0,
"title": "Conclusion and Final Thoughts",
"summary": "Conclusion of the video with final thoughts on the topic."
}
"""
"""
{
"start_ts": 9.72,
"end_ts": 65.6,
"title": "Understanding Language Models",
"summary": "Explains the code-first approach to using language models, suggesting prerequisites such as prior deep learning knowledge and recommends the course.fast.ai for in-depth learning."
}
"""
"""
{
"start_ts": 65.6,
"end_ts": 250.68,
"title": "Basics of Language Models",
"summary": "Covers the concept of language models, demonstrating how they predict the next word in a sentence, and showcases OpenAI's text DaVinci for creative brainstorming with examples."
}
"""
"""
{
"start_ts": 250.68,
"end_ts": 459.199,
"title": "How Language Models Work",
"summary": "Dives deeper into how language models like ULMfit and others were developed, their training on datasets like Wikipedia, and the importance of learning various aspects of the world to predict the next word effectively."
}
"""
# ... other chapters
Alternative Ideas¶
Now that we've seen a complete example of chapter extraction, let's explore some alternative ideas using different Pydantic models. These models can be used to adapt our YouTube transcript analysis for various applications.
1. Study Notes Generator¶
from pydantic import BaseModel, Field
from typing import List
class Concept(BaseModel):
term: str = Field(..., description="A key term or concept mentioned in the video")
definition: str = Field(
..., description="A brief definition or explanation of the term"
)
class StudyNote(BaseModel):
timestamp: float = Field(
..., description="The timestamp where this note starts in the video"
)
topic: str = Field(..., description="The main topic being discussed at this point")
key_points: List[str] = Field(..., description="A list of key points discussed")
concepts: List[Concept] = Field(
..., description="Important concepts mentioned in this section"
)
This model structures the video content into clear topics, key points, and important concepts, making it ideal for revision and study purposes.
2. Content Summarization¶
from pydantic import BaseModel, Field
from typing import List
class ContentSummary(BaseModel):
title: str = Field(..., description="The title of the video")
duration: float = Field(
..., description="The total duration of the video in seconds"
)
main_topics: List[str] = Field(
..., description="A list of main topics covered in the video"
)
key_takeaways: List[str] = Field(
..., description="The most important points from the entire video"
)
target_audience: str = Field(
..., description="The intended audience for this content"
)
This model provides a high-level overview of the entire video, perfect for quick content analysis or deciding whether a video is worth watching in full.
3. Quiz Generator¶
from pydantic import BaseModel, Field
from typing import List
class QuizQuestion(BaseModel):
question: str = Field(..., description="The quiz question")
options: List[str] = Field(
..., min_items=2, max_items=4, description="Possible answers to the question"
)
correct_answer: int = Field(
...,
ge=0,
lt=4,
description="The index of the correct answer in the options list",
)
explanation: str = Field(
..., description="An explanation of why the correct answer is correct"
)
class VideoQuiz(BaseModel):
title: str = Field(
..., description="The title of the quiz, based on the video content"
)
questions: List[QuizQuestion] = Field(
...,
min_items=5,
max_items=20,
description="A list of quiz questions based on the video content",
)
This model transforms video content into an interactive quiz, perfect for testing comprehension or creating engaging content for social media.
To use these alternative models, you would replace the Chapter model in our original code with one of these alternatives and adjust the system prompt in the extract_chapters function accordingly.
Conclusion¶
The power of this approach lies in its flexibility. By defining the result of our function calls as Pydantic Models, we're able to quickly adapt code for a wide variety of applications whether it be generating quizzes, creating study materials or just optimizing for simple SEO.